Puedes ver la primera parte de este Post acá
Imagina el siguiente caso, tienes una tienda en línea con un chatbot para responder dudas sobre envíos, precios o productos.
Normalmente, para generar esta funcionalidad se crean preguntas y respuestas prediseñadas, donde el usuario simplemente aprieta un botón y se muestra la respuesta. Pero, ¿Qué pasa si quiero que mi chat sea inteligente? Podríamos emplear algún modelo de lenguaje como GPT de OpenAI, LLaMA de Meta o cualquier otro modelo de lenguaje. Sin embargo, ahí dependeríamos de la información que tuvo para entrenar, por lo que es muy difícil que el bot sepa cuando volverá a estar disponible la BananaHoodie de MonkeyShop.
Para solucionar el problema de brindar contexto existen distintas alternativas, una es aplicar una técnica conocida como Fine-Tuning que, en pocas palabras, es continuar entrenando el modelo para que se comporte de una forma específica. Sin embargo, esto posee un par de dificultades:
- En caso de querer agregar o eliminar información, requiere volver a entrenar el modelo
- Requiere un equipo que entienda las plataformas y modelos para realizar la operación
- Además, se necesita un gran volumen de datos procesados y analizados para ser entregados al modelo
Otra opción es simplemente darle el contexto en el mensaje. Por ejemplo:
Eres una IA que responde preguntas de clientes teniendo en consideración lo siguiente:
- El stock de los BananaHoodies volverá en 2 semanas
- Los envíos de calcetines se demoran entre 3 a 5 días ….
Y en general el chatbot responderá correctamente; sin embargo, esto también posee un problema grande al enviarlo como contexto sin nada más:
- Requiere enviar el mensaje completo frente a cualquier pregunta. Lo cual es más caro y considerablemente más lento
- Requiere modificar el código cada vez que se agrega algún nuevo tipo de información (Lo cual es tedioso y además requeriría tiempo)
- Se limita la cantidad de contexto que se le puede dar al modelo. Por lo que en caso de que se tenga mucha información, el desafío se complica considerablemente
Embeddings
La tercera opción, que es la mejor manera de resolver este problema, es usar Embeddings. Un embedding es simplemente una representación numérica de un texto. Lo que permite comparar que tanto se parecen dos frases.
OpenAI, además de proveer el servicio de modelos de lenguaje como ChatGPT o GPT-4. Permite acceder al servicio de cálculo de embeddings empleando su modelo text-ada-002. Este modelo devuelve un vector con 1536 valores, los cuales son la representación numérica del texto enviado.
Por ejemplo, si calculamos el embedding de una frase como “Para imprimir 10 veces platanus en Ruby se hace con: ….” Obtenemos un vector que representa dicha frase y su sentido
Ahora ya con los embeddings calculados, la idea es almacenar los textos en conjunto a su representación en Embedding. Normalmente, los textos se almacenan en una base de datos vectorial, debido a su velocidad y funcionalidades pre-hechas. Sin embargo, para simplificar este ejemplo simplemente las guardaremos en un array.
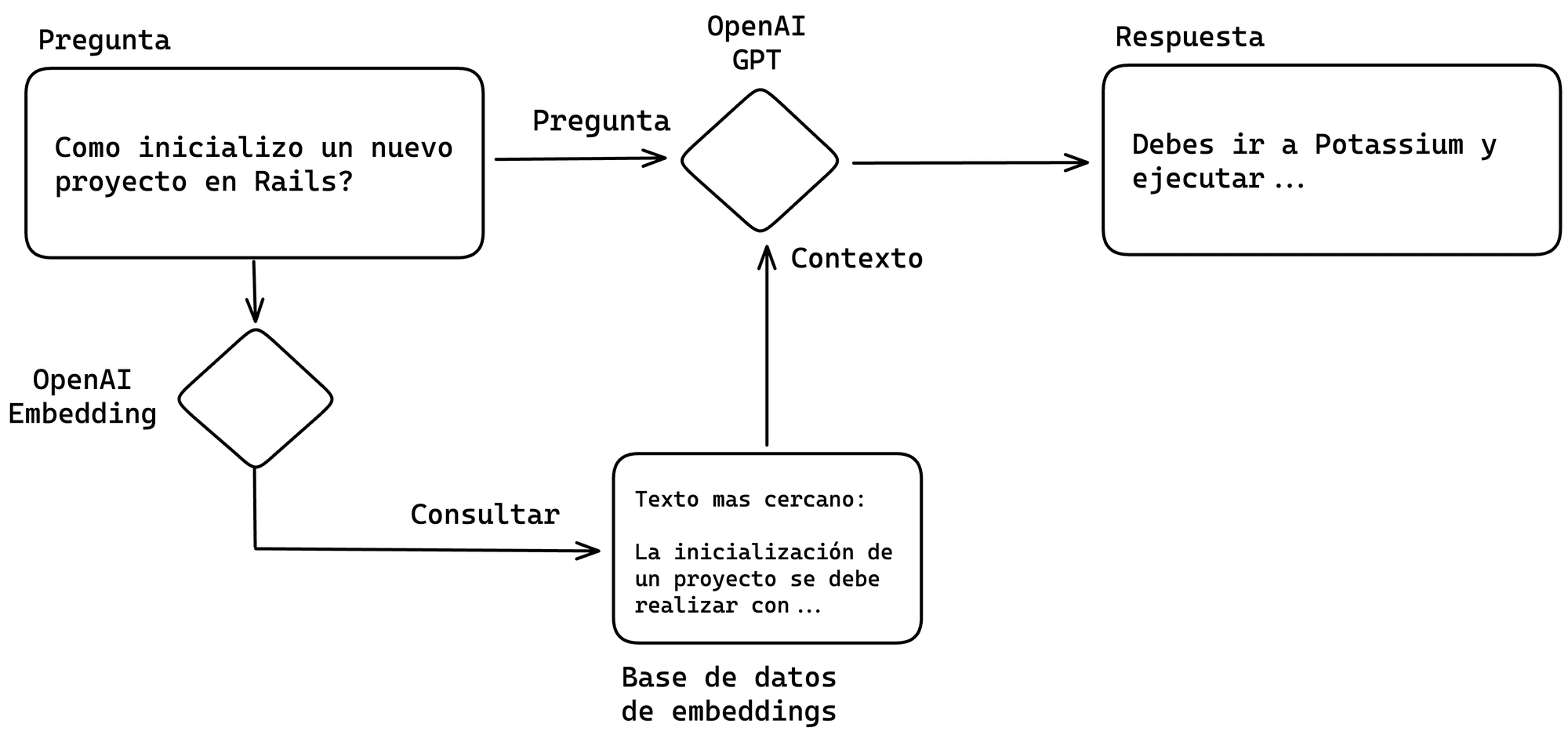
Finalmente, al recibir una consulta, se calculará el embedding de la pregunta y se buscará el más similar. El texto más cercano encontrado será utilizado como contexto en la conversación con el bot.
El proceso en 3 pasos es el siguiente:
- Se recibe la pregunta del usuario
- Se calcula el embedding de la pregunta y se busca el contexto más similar usando este número.
- Se envía la consulta potenciada con el contexto a la inteligencia artificial
Como utilizar embeddings en Ruby
Para calcular los embedding, ya sean preguntas de un usuario o secciones de documentos, emplearemos la API de OpenAI. Posteriormente, almacenaremos estos datos y finalmente podremos calcular que tanto se parece la pregunta del usuario a nuestros textos almacenados.
El código puede parecer algo complejo, pero en una aplicación real existen servicios que se encargan de todo el proceso de almacenar y encontrar el texto más similar utilizando embeddings. Algunos de estos son, PGVector, Pinecone, Milvus, entre otros.
Lo primero que realizaremos es una función auxiliar que nos permite calcular la distancia entre dos vectores. Esta distancia nos indicará que tan cercanas son dos frases en su sentido. Por ejemplo, si una frase es “El perro dice woof” y otra es “El gato dice meow” La distancia entre sus embeddings será poca. Pero una frase como “Juan fue a su trabajo” estará muy lejos.
Además, importaremos la Gema de OpenAI, esta gema permite ejecutar todos los llamados a su API utilizando unas funciones muy simples de administrar y así evitando los dolores de cabeza asociados a llamar una API desde cero. También, importaremos dotenv para así cargar nuestra API Key desde un archivo de variables de entorno
require 'openai'
require 'dotenv/load'
def cosine_distance(vector_a, vector_b)
sum = 0
vector_a.each_with_index do |a, i|
b = vector_b[i]
sum += a * b
end
sum
end
Posteriormente, definiremos nuestra función para obtener el embedding de un texto utilizando la API de OpenAI
def get_text_embedding(text, engine='text-embedding-ada-002')
openai_client = OpenAI::Client.new(access_token: ENV['OPENAI_API_KEY'])
embedding = openai_client.embeddings(
parameters: {
model: engine,
input: [text]
}
)
embedding.dig('data', 0, 'embedding')
end
Esta función retornará un array que contiene muchos números. O sea, nuestro embedding
Luego una función para buscar el texto más cercano a lo que ingresaremos
def get_most_similar_text(text, texts, embeddings)
text_embedding = get_text_embedding(text)
similarities = embeddings.map {
|embedding| cosine_distance(text_embedding, embedding)
}
max_similarity = similarities.max
max_similarity_index = similarities.index(max_similarity)
texts[max_similarity_index]
end
Solo quedarían dos cosas pendientes, calcular los embeddings para nuestros textos y probar las funciones. Para simplificarnos la vida, utilizaremos el siguiente texto en un archivo texts.txt
No lo llames "mono": Asegúrate de darle un nombre elegante y sofisticado a tu mono de mascota, como Lord Bananington o Duque de Chimpshire. ¡Un mono de alta clase merece un nombre adecuado!
Lecciones de etiqueta: Enseña a tu mono las mejores formas de comportarse en la sociedad. Asegúrate de que siempre sostenga su taza de té con el meñique levantado y de que tenga un repertorio completo de saludos con la pata. ¡Un mono educado es un mono feliz!
Estilo de moda: No olvides el aspecto estilístico de tu mono. Mantén su pelaje siempre brillante y suave con tratamientos de spa de banana y dale una selección de atuendos de moda para que elija. ¡Tu mono será el más elegante del vecindario!
Clases de baile: ¿Qué mejor manera de entretener a tu mono y mantenerlo en forma que con lecciones de baile? Organiza sesiones de baile con música pegajosa y ayúdale a perfeccionar su estilo de baile único. ¡Prepárate para impresionar con los movimientos de tu mono en la próxima fiesta!
Escuela de actuación: ¿Quién dice que los monos no pueden ser estrellas de cine? Inscríbelo en una escuela de actuación para monos y ayúdalo a perfeccionar su interpretación. Quién sabe, ¡podría ser la próxima estrella de Hollywood! Prepárate para recibir llamadas de agentes de cine y paparazzi en tu puerta.
Clase de yoga para monos: Organiza sesiones de yoga especiales para tu mono. Enséñale posturas como el "Mono en la Luna" o el "Saludo al Plátano". ¡Ambos pueden ser muy relajantes y divertidos para tu peludo amigo!
Cuenta de Instagram famosa: Crea una cuenta de Instagram para tu mono y comparte fotos y videos adorables de sus travesuras diarias. No te olvides de usar hashtags populares como #MonkeyBusiness y #SimianStar para obtener más seguidores. ¡Tu mono podría convertirse en una sensación de las redes sociales!
Clases de idiomas: ¿Por qué no enseñarle a tu mono algunos trucos lingüísticos? Inscríbelo en clases de idiomas y sorprende a tus amigos cuando tu mono empiece a hablar francés o chino. ¡Tal vez incluso puedas llevarlo contigo de vacaciones como tu propio intérprete personal!
Fiesta de cumpleaños temática: Celebra el cumpleaños de tu mono con una fiesta temática épica. Decora la casa con globos y plátanos, invita a otros amigos con mascotas disfrazadas y asegúrate de tener un pastel de banana para el gran momento. ¡Tu mono se sentirá como una verdadera estrella!
Entrenamiento de superhéroe: Ayuda a tu mono a descubrir sus superpoderes internos entrenándolo como un auténtico superhéroe. Enséñale a saltar de árbol en árbol como Spider-Monkey o a lanzar plátanos como el Hombre Plátano. ¡Juntos podrían salvar el día y proteger la ciudad!
Calculamos los embeddings de todos esos textos y los guardamos
texts = File.readlines('texts.txt').map(&:chomp) # Extraemos cada linea
embeddings = @texts.map { |text| get_text_embedding(text) } # Calculamos su embedding
Y finalmente llamamos a nuestra función
puts get_most_similar_text('Que nombre deberia dar a mi mono?', texts, embeddings)
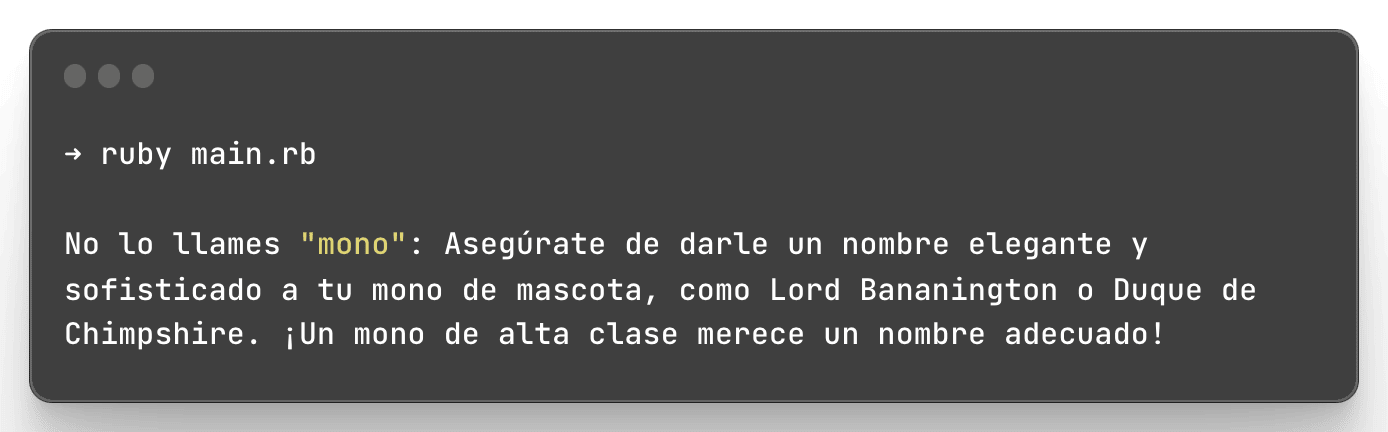
Y funciona perfecto!, ya tenemos una forma de buscar en nuestros documentos usando Embeddings. Ahora, ¿Cómo empleamos este conocimiento para potenciar los modelos de lenguaje que existen?
Potenciar ChatGPT utilizando Embeddings
Lo que debemos hacer ahora es simplemente generar la respuesta de GPT, pero pasándole el texto que encontramos como contexto. Para esto definiremos primero la función que llamara a OpenAI para generar la respuesta
def get_chat_response(messages)
result = @openai_client.chat(
parameters: {
model: 'gpt-3.5-turbo',
messages: messages
}
)
result.dig('choices', 0, 'message', 'content')
end
Posteriormente, la función que generará los mensajes para de esa forma ingresar el contexto
def get_enhanced_chat_response(question, texts, embeddings)
most_similar_text = get_most_similar_text(question, texts, embeddings)
messages = [
{ 'content': 'Considera el siguiente contexto como contexto para responder a las preguntas que te haga: ',
'role': 'system' },
{ 'content': most_similar_text,
'role': 'system' },
{ 'content': question,
'role': 'user' }
]
get_chat_response(messages)
end
Finalmente, solo nos queda llamar la función!
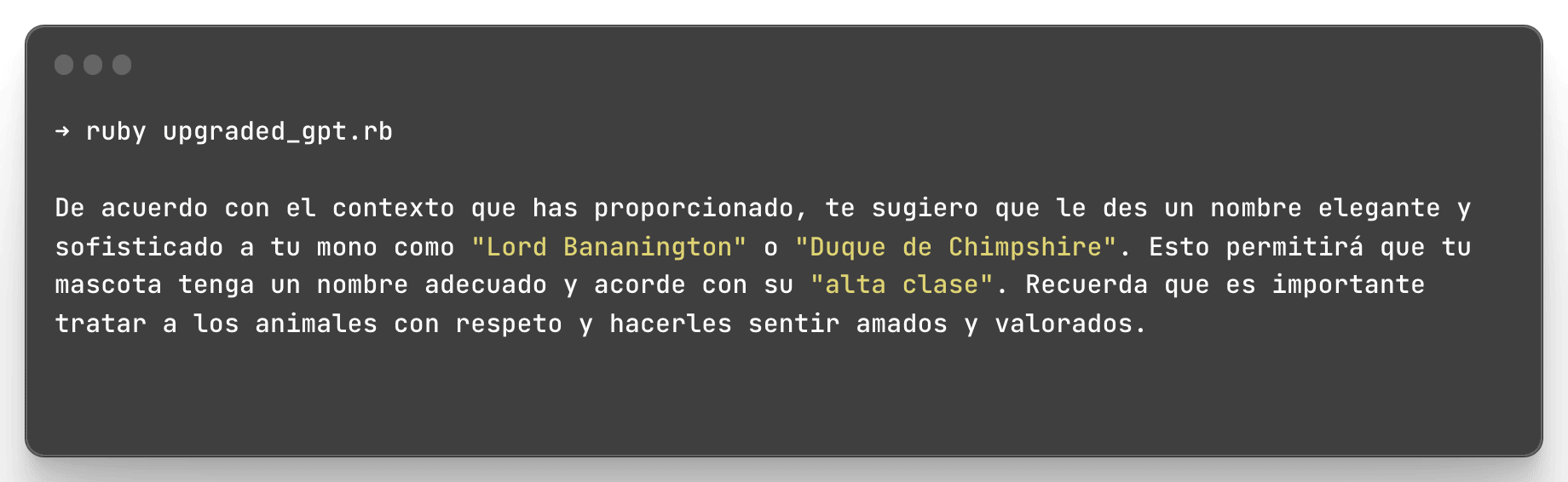
Aquí podemos notar que nuestro programa no solo entregó el texto que encontró al buscar utilizando embeddings, sino que generó una respuesta totalmente nueva que usa nuestro texto como contexto.
Próximos pasos y conclusión
¿Cómo podemos continuar mejorando nuestro sitio? Ya teniendo conocimiento sobre embeddings y de como utilizar OpenAI se nos abren muchas posibilidades, por ejemplo:
- Utilizar plataformas de búsqueda en sitios para actualizar la información sin necesidad de ingresarla manualmente
- Hacer que los embeddings apunten a fragmentos de código que luego la IA puede invocar
- Almacenar las preguntas de usuarios y así ver si hay muchos embeddings cercanos para detectar preguntas frecuentes.
Y muchas cosas más! La pregunta es, entonces, ¿Hasta dónde podemos llegar? Creo que queda un largo tiempo hasta que lo descubramos.


