Como muchas veces durante la semana, estaba revisando un *Pull Request *y me llegó un trocito de código que me quedó dando vueltas. “Si en vez de un punto pones un guión bajo debería ahorrarse mucha memoria, cierto?”
Resultó ser que sí, por lo que me animé a escribir este post para compartirles la enseñanza.

Veamos este ejemplo en Rails
Tenemos 3 modelos AdminUser , BankMovement y BankMovementCheck. El último es un modelo intermedio para que un usuario pueda marcar los movimientos bancarios. Las relaciones son las siguientes:

Ahora, supongamos que queremos saber si un movimiento fue marcado por un user en específico: ¿En qué se diferencian estos dos métodos?
Como lo anticipa la introducción, la única diferencia es que a la izquierda de la igualdad se cambio un **punto **por un guión bajo.
Ok, ¿y cómo afecta esto a Boca?
Aunque la diferencia en código sea literalmente de 1 caracter, el significado detrás de cada método es **muy diferente. **Hint: El primero es mucho más ineficiente que el segundo.
Lo que realmente los diferencia es que en el primer método estamos cargando el admin_user en memoria para consultar por su id. En cambio en el segundo, solo se está accediendo al atributo admin_user_id de la instancia bank_movement_check (que se carga en ambos métodos). Es decir, nuestro método eficiente se ahorra la carga de un objeto completo.
Muy bonito, quiero ver los números.
Para ejemplificar lo significativa que es esta diferencia, veamos un análisis (no científico) en cuanto a consultas, uso de memoria y tiempo de ejecución.
Consultas
Nuestro método eficiente _marked_by_user? (con _ al inicio de su nombre) hace una consulta menos a la base de datos
Memoria
Utilizando gema benchmark/memory probamos el uso de memoria de ambos métodos, tanto al ser ejecutados por primera vez como para N ejecuciones consecutivas:

Podemos ver que el uso de memoria baja de 2.325M a **1.230M **para la primera llamada al método, lo que significa un ahorro de casi un 50% 🤯. Por su parte, en llamadas consecutivas la baja es de 30.776k a 15.019K.
La abismal diferencia entre el primer intento y los siguientes se debe a que el objeto (o parte de él) permanece cargado en memoria/caché y no es necesario cargarlo completo como en el primer intento.
Tiempo
Ahora utilizando la librería Benchmark de Ruby, medimos los tiempos de ejecución:
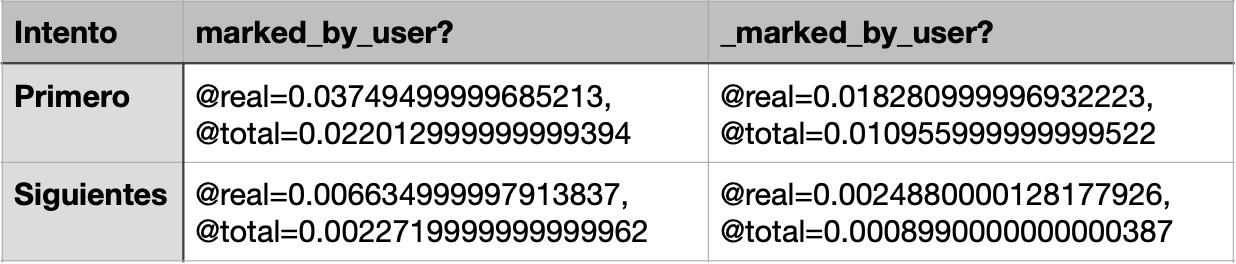
Nuevamente el ahorro es significativo. El método ineficiente toma 0.022013s mientras que el eficiente 0.010956s , es decir, casi el doble de tiempo. Para los siguientes intentos, la diferencia es aun mayor, el método eficiente hace la tarea en aproximadamente un tercio del tiempo.
Nuevamente el caché y la memoria hacen que haya una diferencia importante entre la primera llamada al método y las siguientes.
Conclusión
Un ínfimo cambio en el código nos trajo un tremendo boost en performance. Imagina el impacto de esto en una app con cientos o millones de operaciones como esta. Lo importante a rescatar es que vale la pena estar atento a estos detalle y a qué está haciendo realmente nuestro código. Si bien este ejemplo es en Ruby, en todos los lenguajes y frameworks existen estas sutilezas como esta.
¿Cómo encontrar problemas de este estilo al desarrollar o probar?
Siempre analiza la consola en búsqueda de consultas innecesarias
Instala plugins de *memory-profiling *y performance en general, pueden ayudar a detectar métodos o endpoints ineficientes. En Platanus usamos Scout
Intenta entender qué hace tu código a más bajo nivel
Realiza *Code Review, *siempre pueden aparecer sugerencias como esta!


