Era la primera lluvia de invierno y Claudia, una simple mortal, estaba trabajando en su casa haciendo su proyecto final de computación. La luces tintineaban, el frío entraba por la ventana y el tiempo para entregar su trabajo pasaba.

Claudia estaba tranquila a pesar de que en el reloj tocaban las 10:30 pm y le quedaba 1 hora y media para hacer entrega de su proyecto final. Nadie pudo anticipar lo que estaba por ocurrir. De un segundo a otro, toda su calle queda en total oscuridad. Pasaron minutos y esa tranquilidad que sentía, rápidamente había abandonado su cuerpo. Ahora la histeria de si volvería la luz, o peor, de si su trabajo quedaría guardado, se apoderaba de ella.

Quedaban 10 minutos y volvió la luz. La pantalla del computador se enciende y con temor ingresa su contraseña. Claudia no se animaba a abrir los ojos. De a poco se armó de valor, y no pudo creer lo que vió. En el centro de su escritorio estaba un archivo “Trabajo_final_v1.py”. Claudia, si bien era un simple mortal, era uno bastante inteligente pero con pésima memoria. Minutos antes del incidente había guardado una versión en su computador, que afortunadamente le salvó el día.

No sé tu, pero si bien nunca me ha pasado exactamente lo que le pasó a la señorita Claudia, si he pasado por sustos similares #TodosSomosClaudia. Cuántas veces nos hemos visto guardando archivos como Informe-final.pdf, Informe-final-ahora-sí.pdf o Informe-final-de-los-finales.pdf.
Bueno, creería que más de una vez te ha pasado. Quedarnos con diferentes versiones de un mismo archivo, nos permite llevar registro o un historial de los cambios que vamos realizando. Esto tiene nombre y apellido, se le conoce como un sistema de manejo de versiones.
El manejo de versiones es un sistema que nos permite llevar registro de los cambios realizados sobre un mismo archivo. Si cometimos un error en una de las versiones no será el fin del mundo y podríamos tener una segunda (o tercera, cuarta, quinta, etc.) oportunidad.
Los sistemas de manejo de versiones (VCS) han ido evolucionando y creciendo, comenzando por ser esa simple práctica de ir guardando diferentes versiones en nuestro computador. Sin embargo, estos tenían un problema, no escalaban bien en equipos.
Imagina que tú y un compañero están programando juntos. Si el sistema se maneja localmente, es decir, cada uno tiene su propia versión en su computador al cual le van agregando cosas, tendría que avisarle al otro qué hizo y qué cambió al enviárselo, para que después él, en su versión en local haga los cambios. ¿Suena fome y latero? Sí que lo es, trabajar colaborativamente sería muy tedioso y lento. Es por eso que evolucionó a otros sistemas de manejo de versiones, los centralizados y los distribuidos.
Estos sistemas de manejo de versiones graban los cambios realizados en un proyecto. Nos permiten ver el historial, ver los cambios realizados, quién los realizó y qué fue lo que cambió (escuchar “Every breath you take - The Police” para más dramatismo). Ahora bien, ¿En qué se diferencia un sistema de manejo de versiones centralizado (CVCS) o distribuido (DVCS)?
En un VCS centralizado todos los miembros del equipo consultan a un repositorio centralizado para obtener la última versión del código y también para compartir en lo que avanzaron. Ya no tenemos todos nuestra propia versión en local si no que esta está en un servidor centralizado y es este proyecto al cual la gente le agrega los cambios. Un ejemplo de este sistema es Google Drive. El problema con esto, es que si el servidor falla perdemos la posibilidad de compartir nuestros cambios.
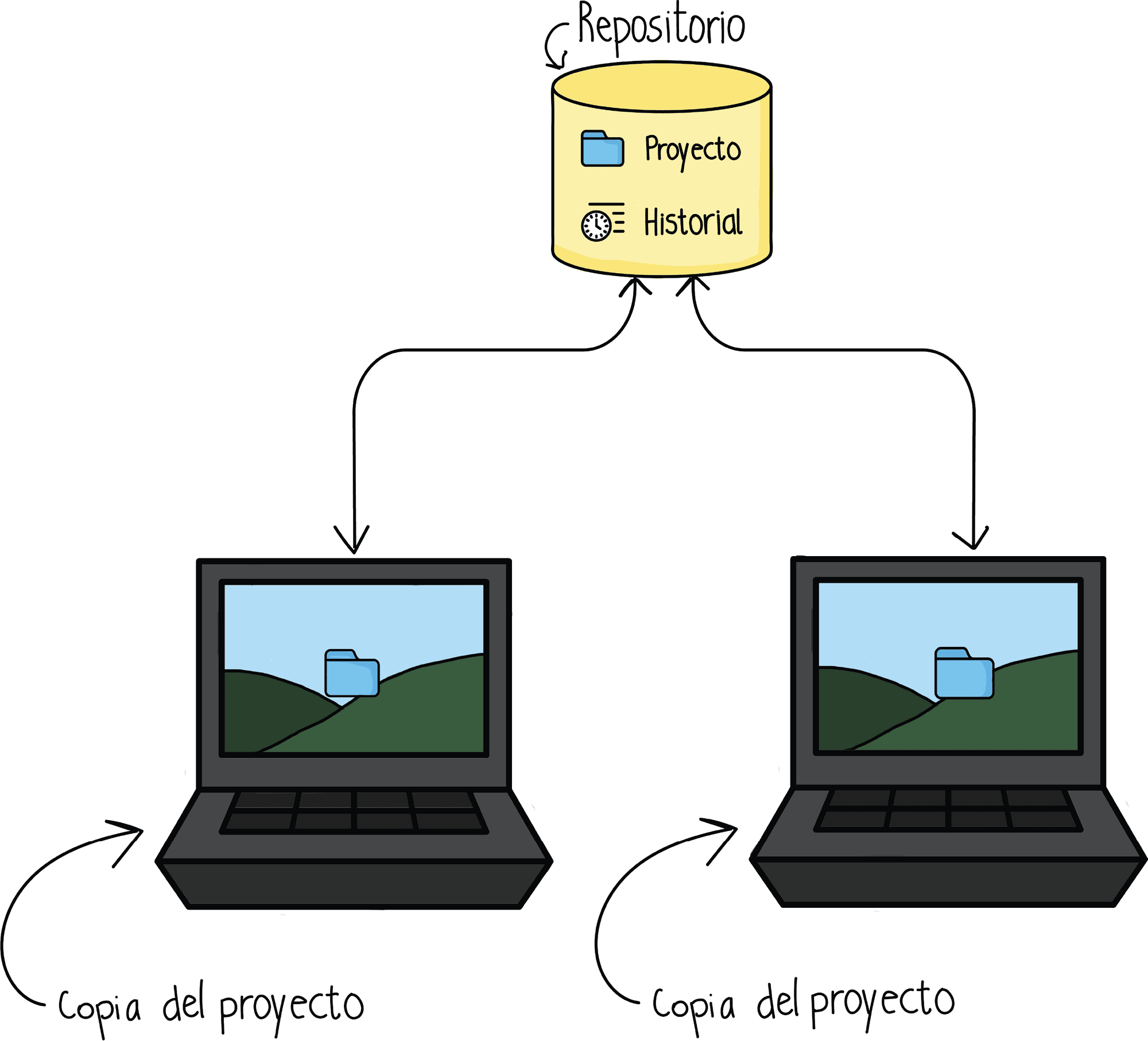
Por otro lado, los distribuidos consisten en que cada uno tiene una copia del proyecto en local, pero no solo de eso, sino que también del historial del proyecto. De esta manera si el servidor se cae, cualquiera puede restaurar el proyecto fácilmente con alguna de las copias que tienen los colaboradores en local.
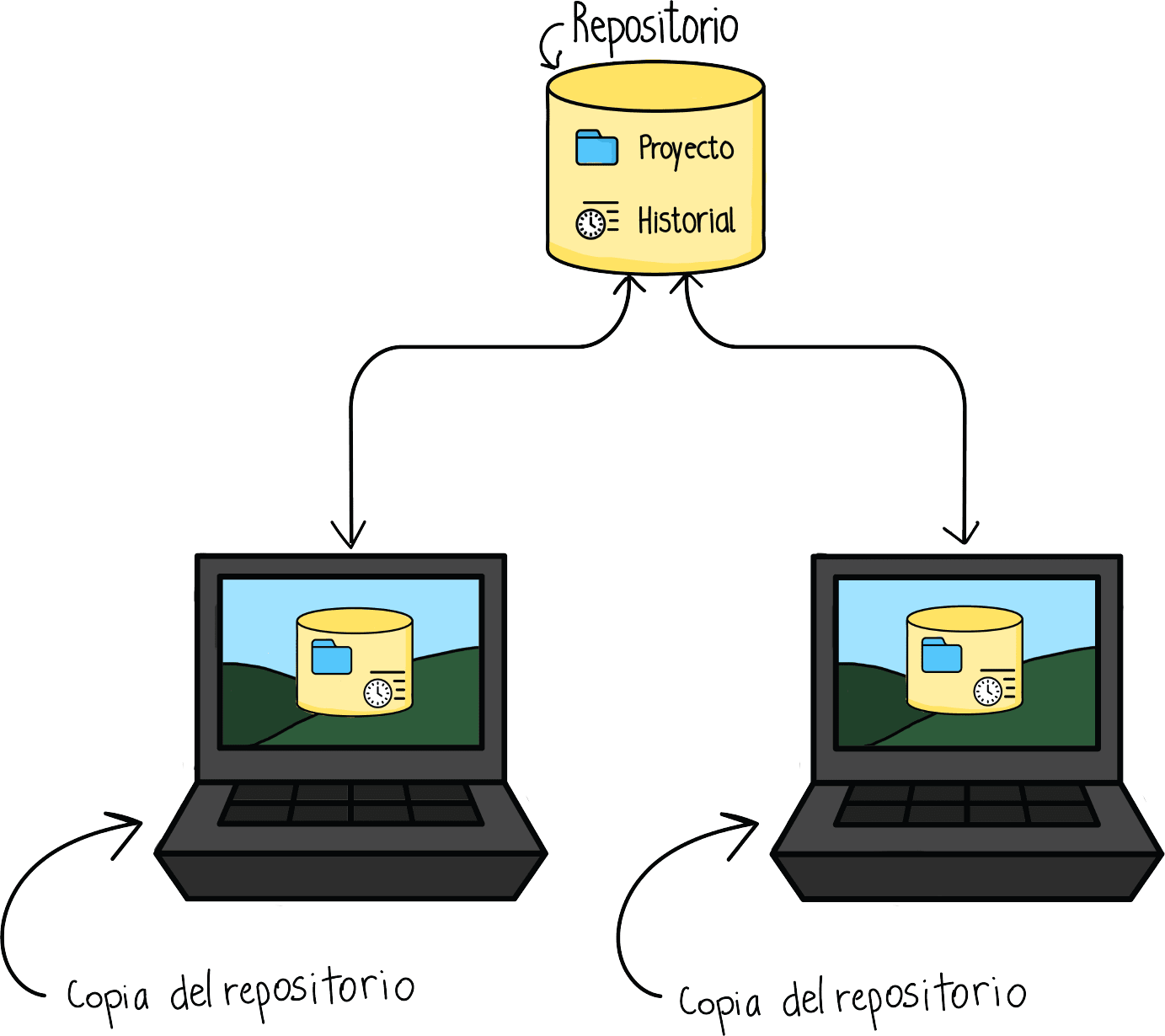
Te preguntarás, ¿qué es todo esto y qué tiene que ver con lo que nos convoca, lo cual es explicar qué es Git? Git es una tecnología de sistemas de control de versiones distribuidos y una de las más populares en el mundo computín.
Todo comenzó el 2002 cuando un proyecto de Linux, Linux kernel, empezó a utilizar la herramienta Bitkeeper. Este era un DVCS que utilizaban para poder trabajar en la mantención del proyecto. Sin embargo, el 2005 hubo un giro inesperado. En palabras simples, el equipo de Bitkeeper y Linux se empezaron a llevar mal. Bitkeeper decidió empezar a cobrarle por los servicios y Linux en respuesta lo eliminó por convivencia.
¿Qué haría Linux ahora para poder seguir con el mantenimiento? Linus Torvalds, al volver de unas vacaciones de trabajo, además de volver con un imán de souvenir, vuelve con la idea de crear su propio sistema de manejo de versiones, el cual conocemos hoy en día como Git.
Esta herramienta la hizo con el fin de crear una versión mejorada de lo que existía y solucionar algunos de los dolores que habían tenido utilizando Bitkeeper. Es por esto que querían que esta tecnología fuera más rápida, simple, que permitiera paralelizar el desarrollo, que fuera completamente distribuida y que permitiera manejar proyectos muy grandes sin comprometer la velocidad.
Según la git-scm la idea de Linus Torvalds era cambiar la forma en que se piensa guardar información. Otros sistemas de manejo de versiones piensan la información que guardan como una lista de archivos, que al subir cambios, el sistema debe comparar cada uno con la versión anterior e ir guardando las diferencias, a las cuales se les conoce como “deltas”.
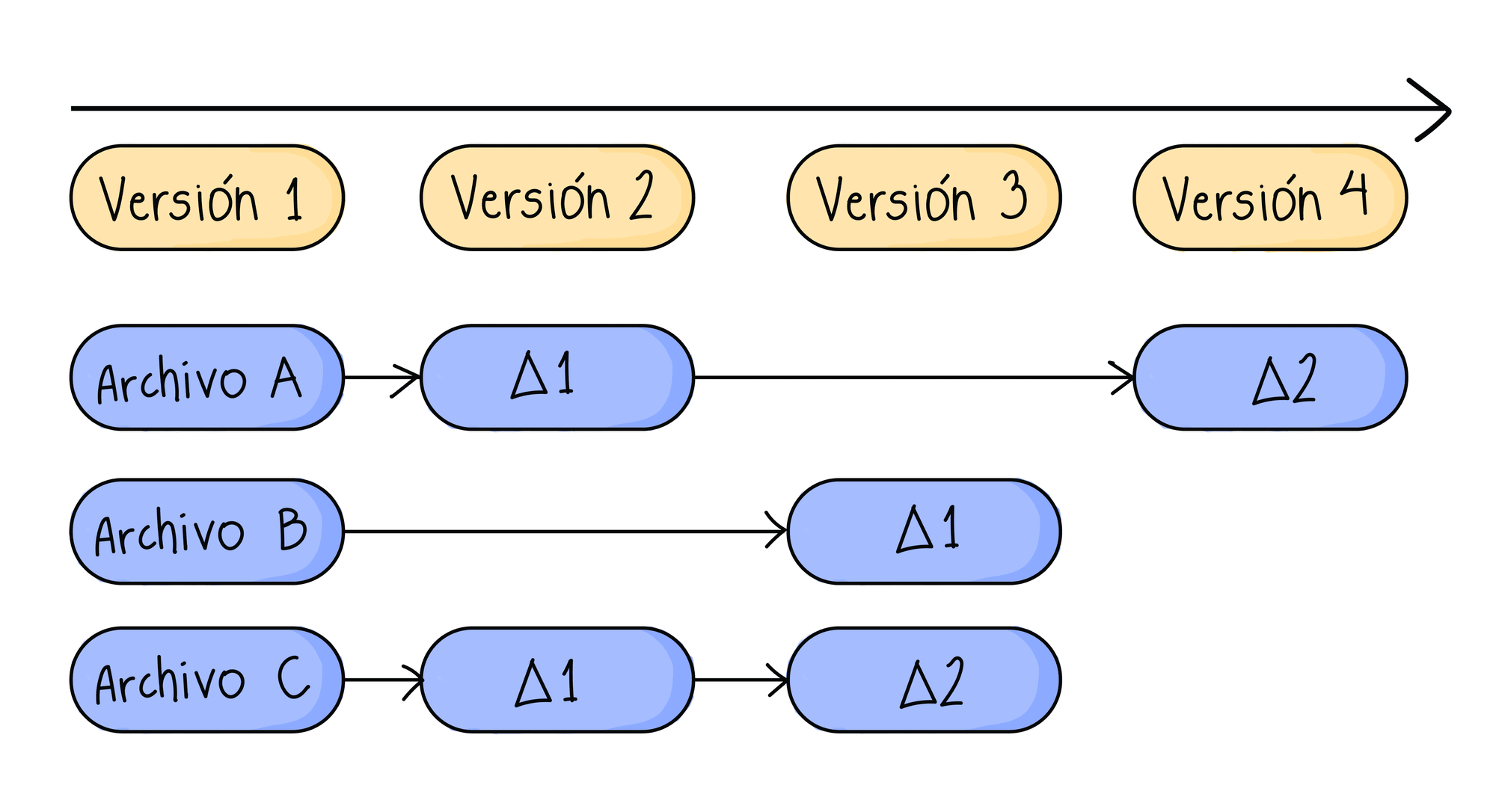
Sin embargo, Git no sigue esta misma lógica. Cada vez que guardas un proyecto, le estas sacando una foto a como se ven todos los archivos en ese mismo instante. Si los archivos cambiaron, se guarda esa nueva foto y si no, no se guarda de nuevo si no que se hace una referencia al archivo de la versión anterior.
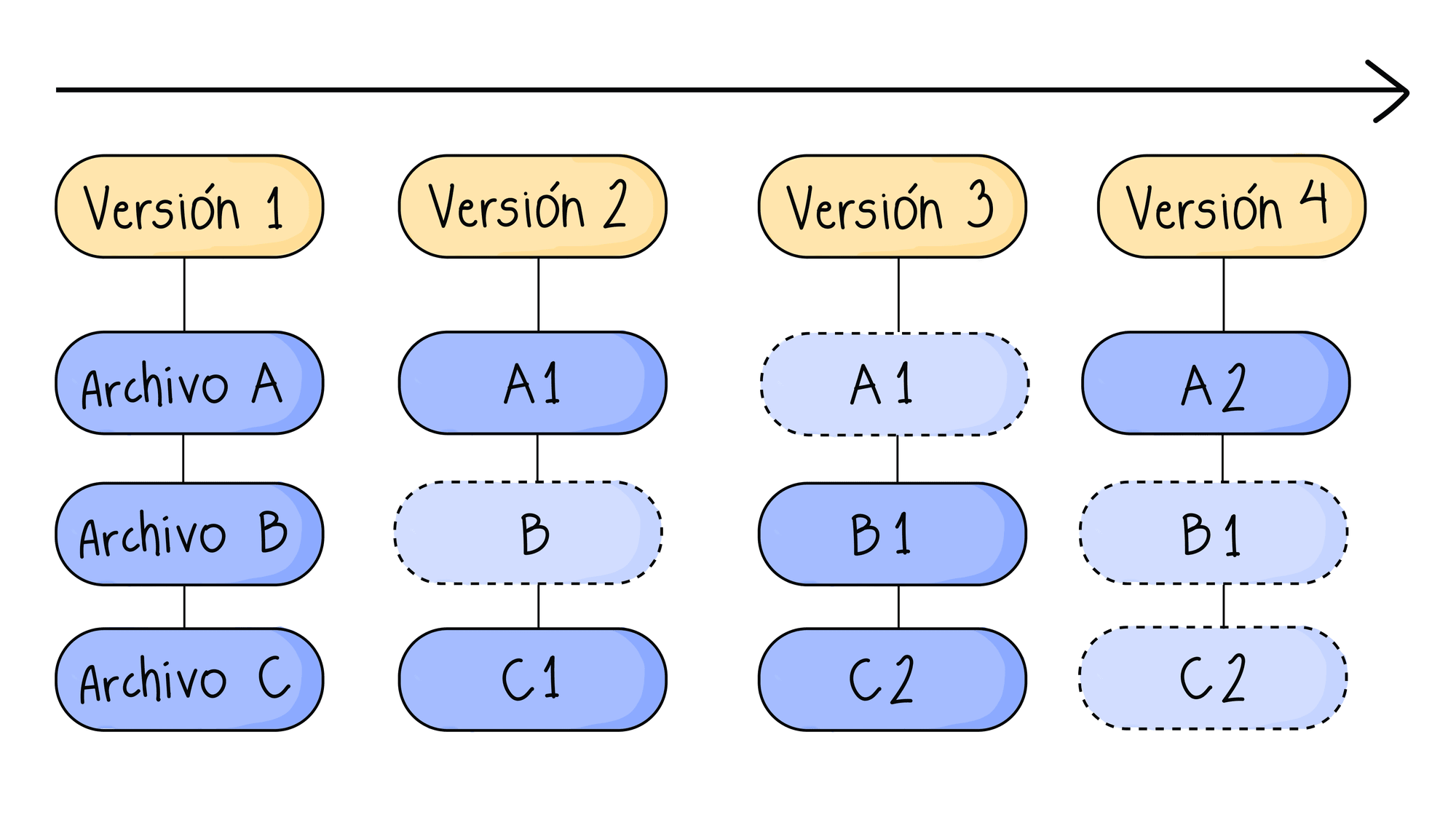
Entonces, ¿cómo funciona Git? Todo comienza con un repositorio de trabajo. Un repositorio es un lugar en donde guardamos nuestro proyecto. Este puede ser un repositorio local, es decir solo yo en mi computador lo puedo ver, o remoto, lo puede ver todo el equipo con el que trabajo.
Git funciona por medio de comandos que puedes ejecutar en tu terminal. Si bien existen muchos comandos, en este post te quiero introducir los principales por medio de un ejemplo. Imagina que quieres hacer un proyecto con dos amigos, una aplicación para agregar filtros a imágenes. En primer lugar deberás crear el repositorio remoto que después tus compañeros, utilizando el comando git clone <url>, podrán copiar en sus computadores.
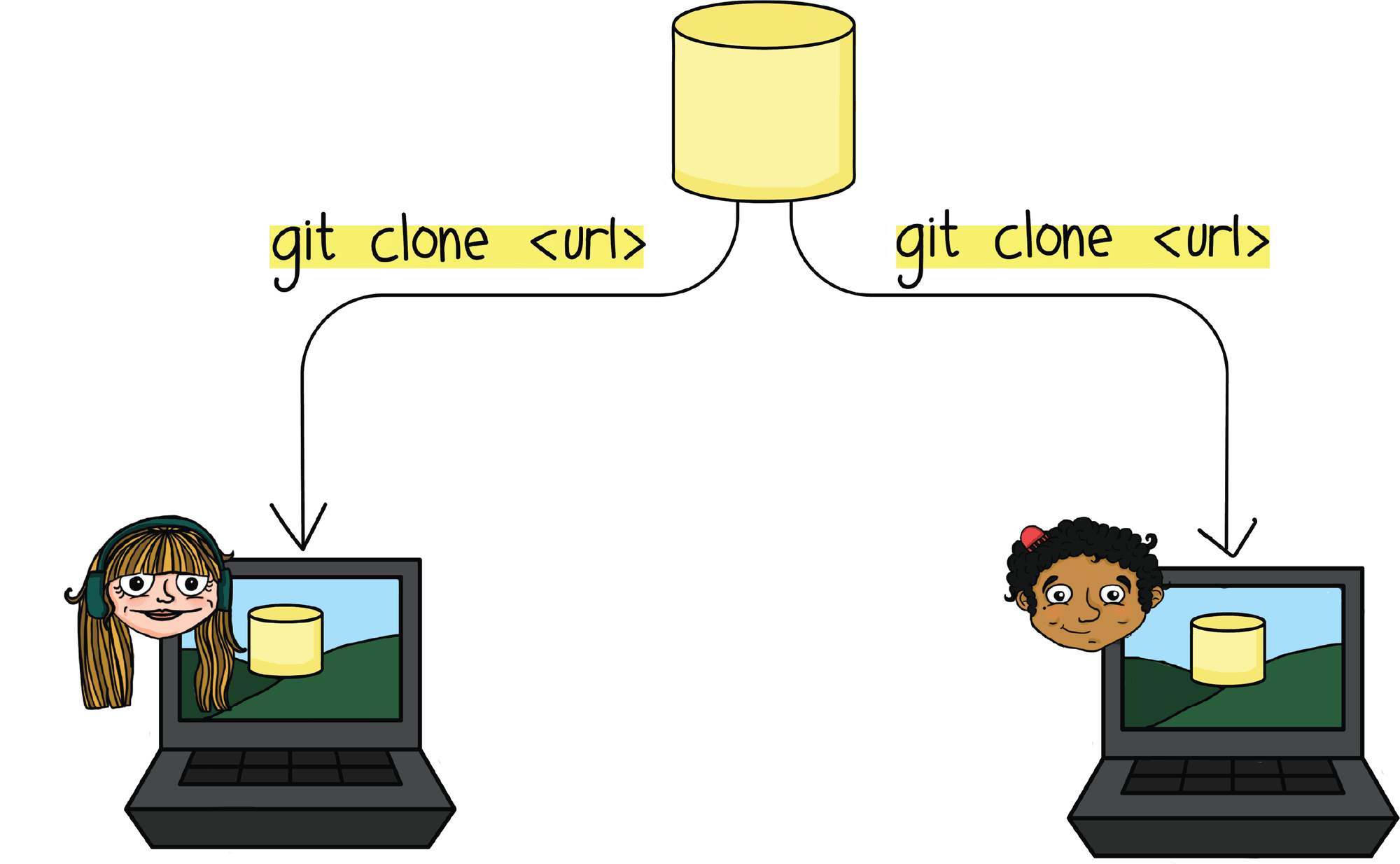
Git funciona en base a lo que conocemos como branches. Una branch o rama es un ramificación de la línea principal de trabajo, piénsalo como cuando Loki alteró su línea de tiempo por lo que crea una nueva al salirse, esto es similar, solo que menos trágico.
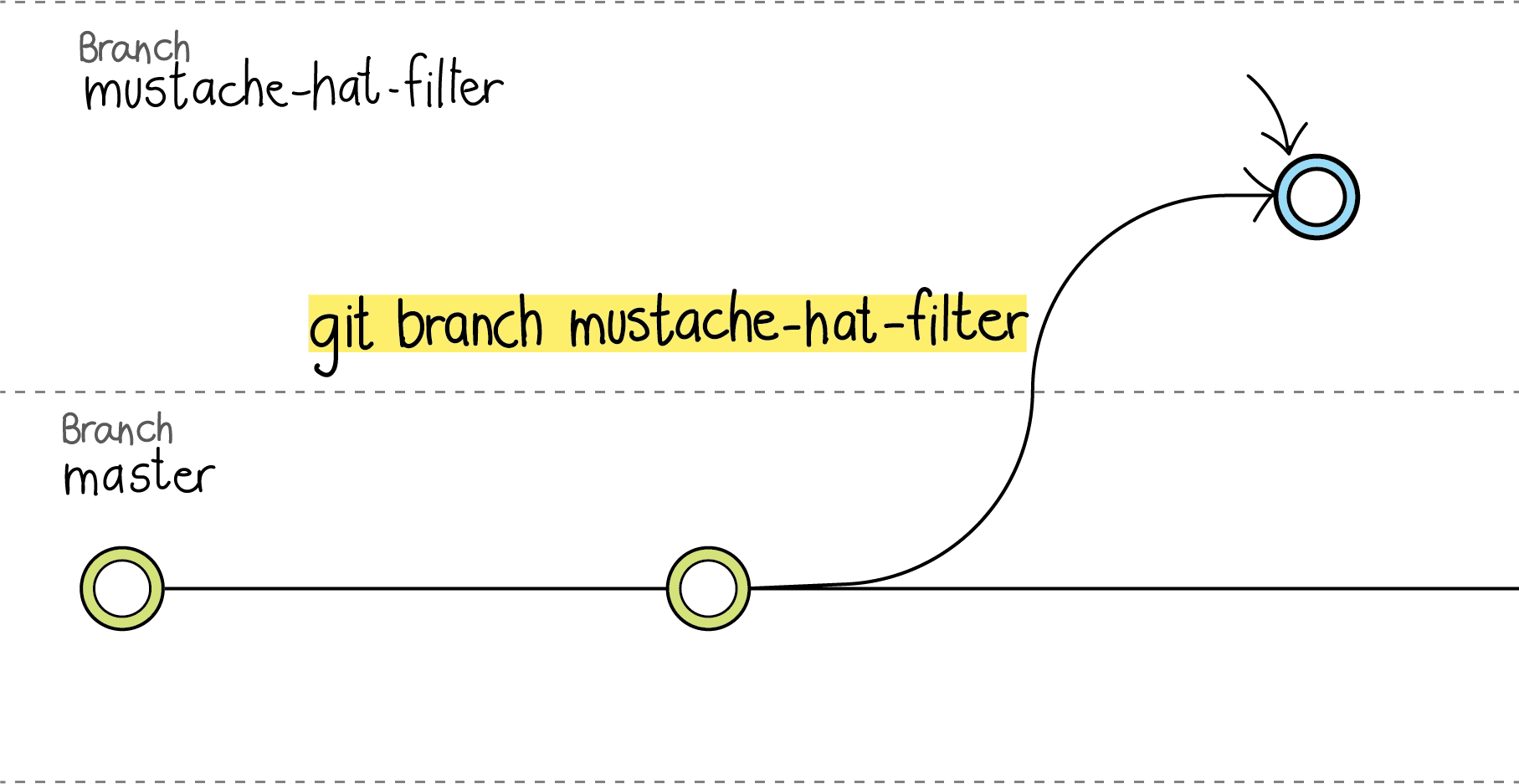
Cuando creas una rama usando git branch <nombre de la rama> haces una copia del proyecto original pero ahora es una línea propia de desarrollo. Entonces si quieres agregar una nueva funcionalidad a tu aplicación lo que tienes que hacer es crearte una rama de trabajo para hacer la implementación.
Volviendo al ejemplo de tu aplicación para agregar filtros, imagina que quieres agregar un filtro que le agregue bigote y sombrero a las imágenes, deberías crear una rama nueva, la cual podrías crear con el comando git branch mustache-hat-filter.
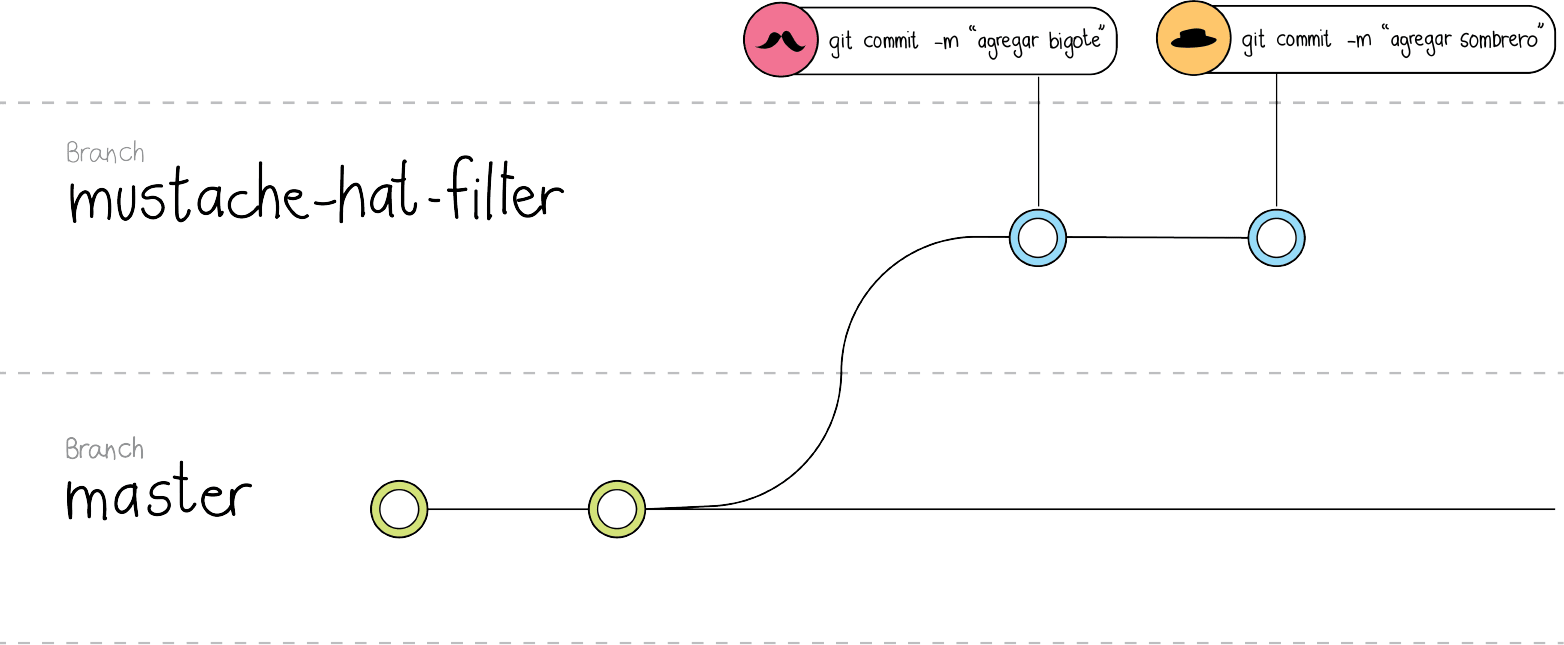
Aquí puedes hacer cuantos cambios quieras y puedes ir registrando los cambios a tú rama de trabajo. A estas pequeñas adiciones se les conoce como “commits”. La idea de los commits es encapsular y registrar esos cambios que están relacionados o que sean pequeños avances con el fin de tener un historial del proyecto más descriptivo. En el caso del ejemplo, el primer commit puede contener los cambios relacionados a agregar el bigote al filtro, y el segundo los cambios donde se agrega el sombrero.
Ahora bien, estos cambios sólo están en tu computador y en esa rama que creaste, por lo que faltaría agregar estos cambios a la rama principal. Es decir, debes unir tu rama a la línea de trabajo original. Con Git, esto lo haces primero cambiando de rama con el comando git checkout master (o como se llame la rama principal).
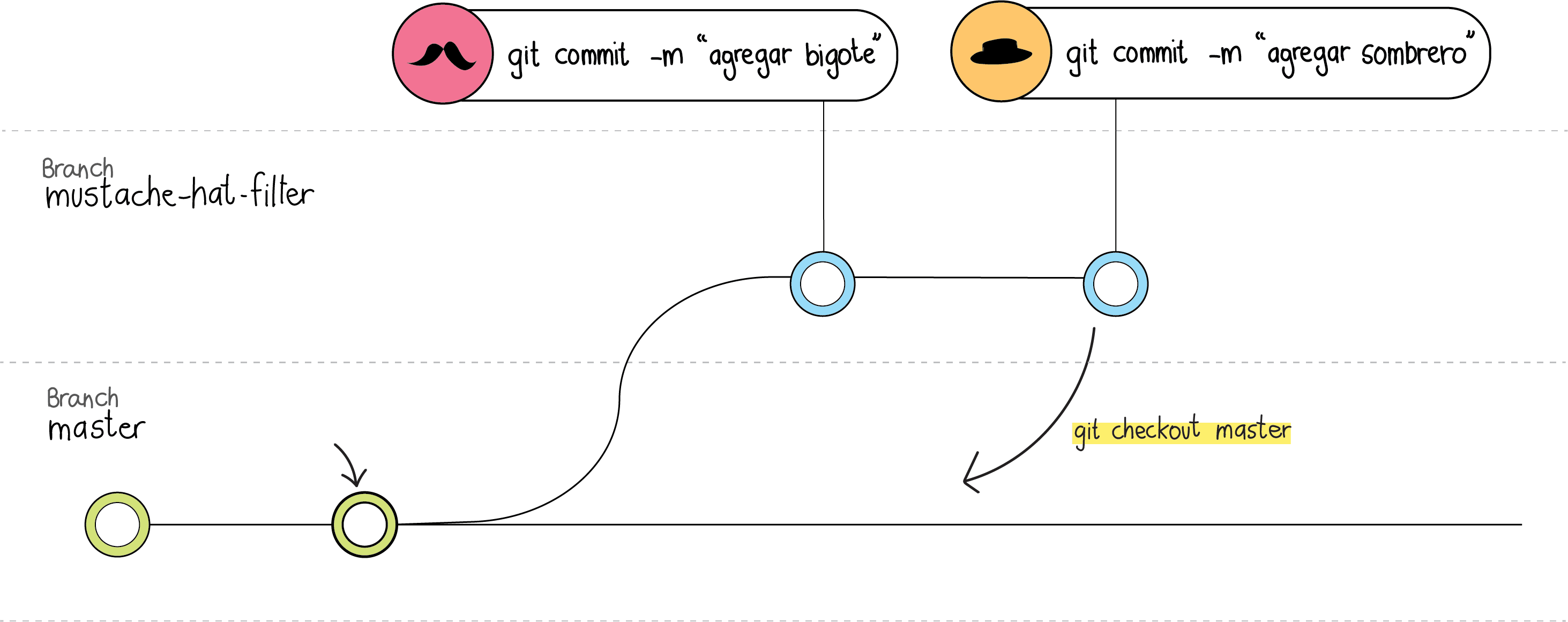
Y después ejecutando el comando git merge <nombre de tu rama>.
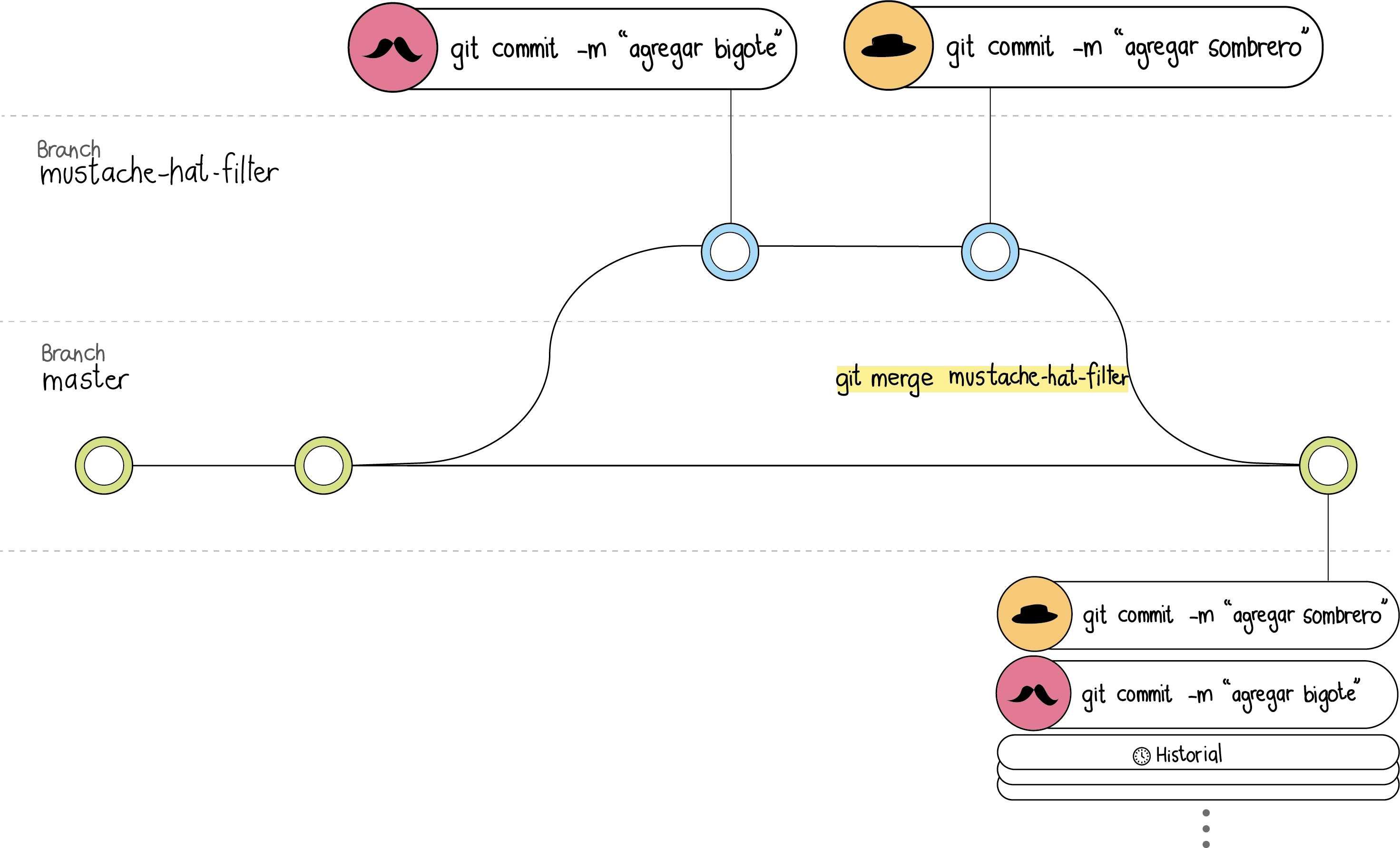
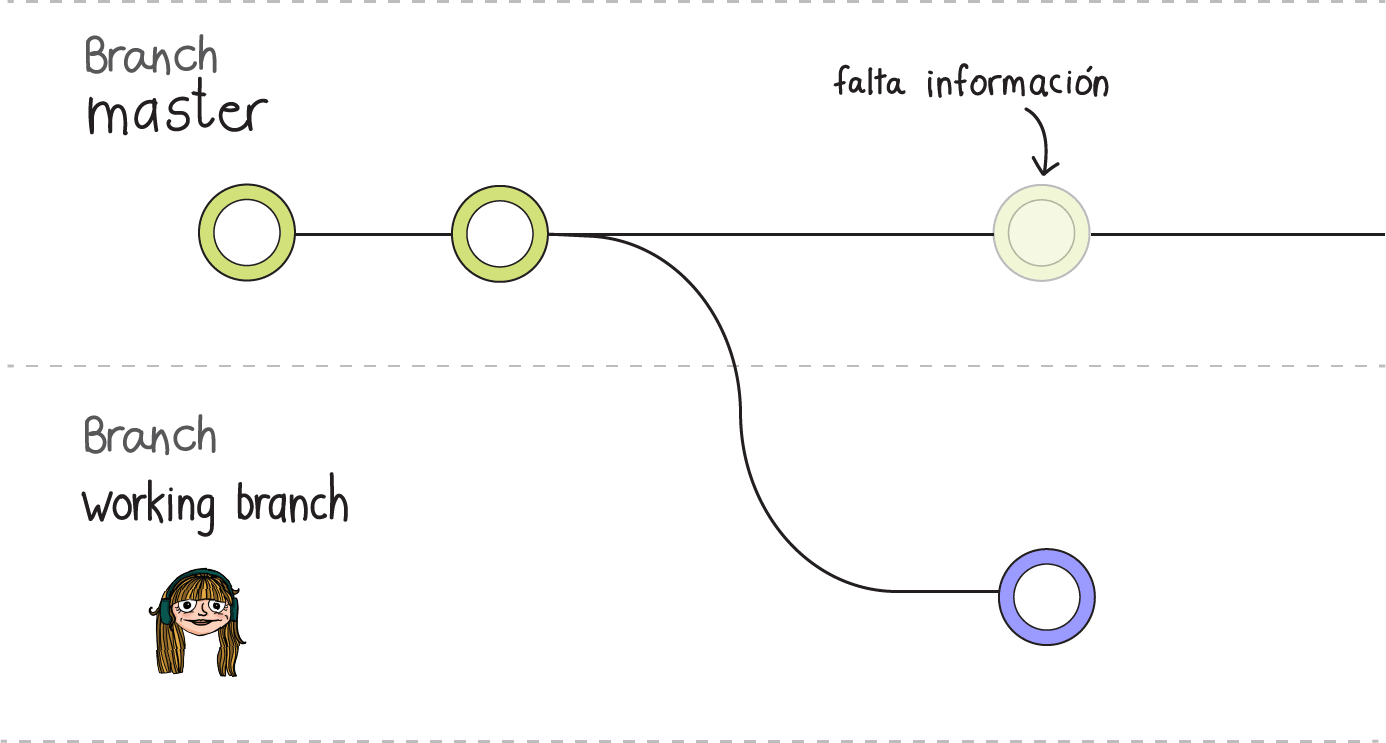
Por último, ¿Qué pasa con tus compañeros?¿Cómo se enteran ellos de tus cambios? Al hacer push, lo que hiciste fue agregar en remoto los cambios que realizaste y los agregaste al historial. Si uno de tus compañeros quiere trabajar, la versión que clonó en un principio estaría desactualizada, por lo que tiene que actualizar su historial en local a la nueva versión.
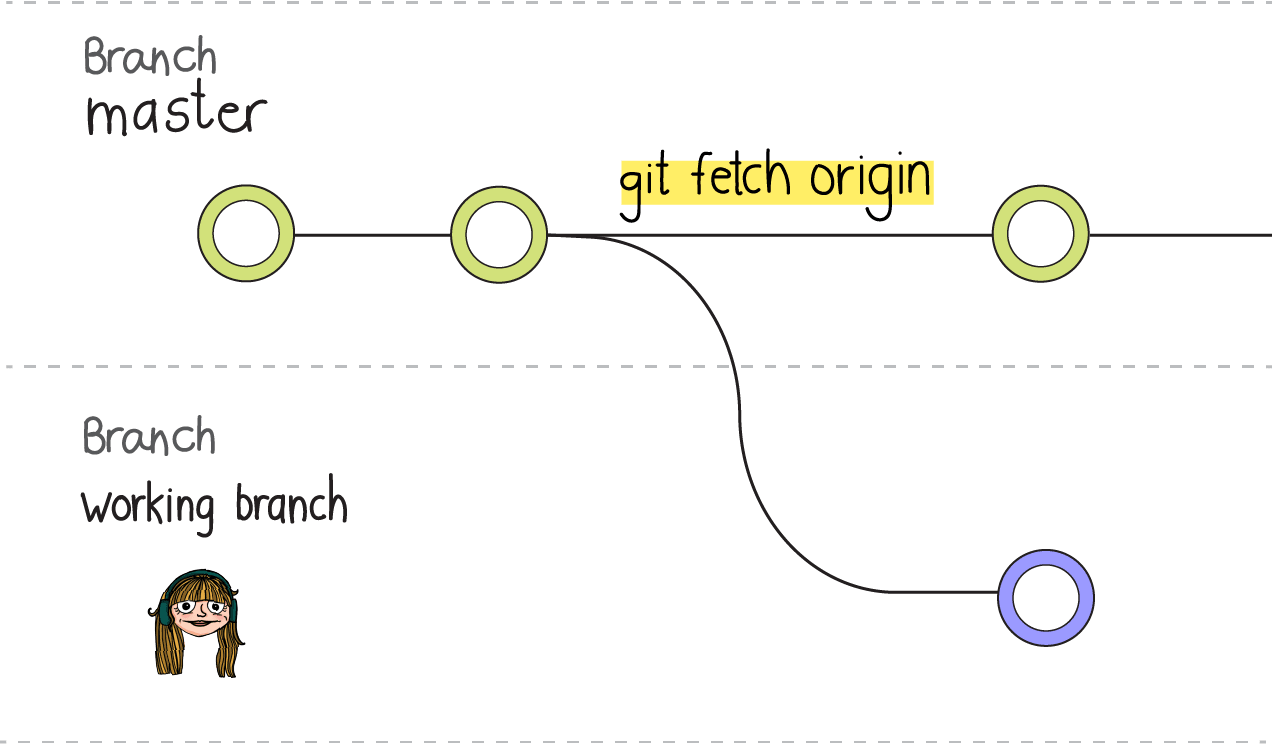
Para hacer esto se usa git fetch origin. Con esto el repositorio se actualiza con los cambios que realizaste en el repositorio remoto.
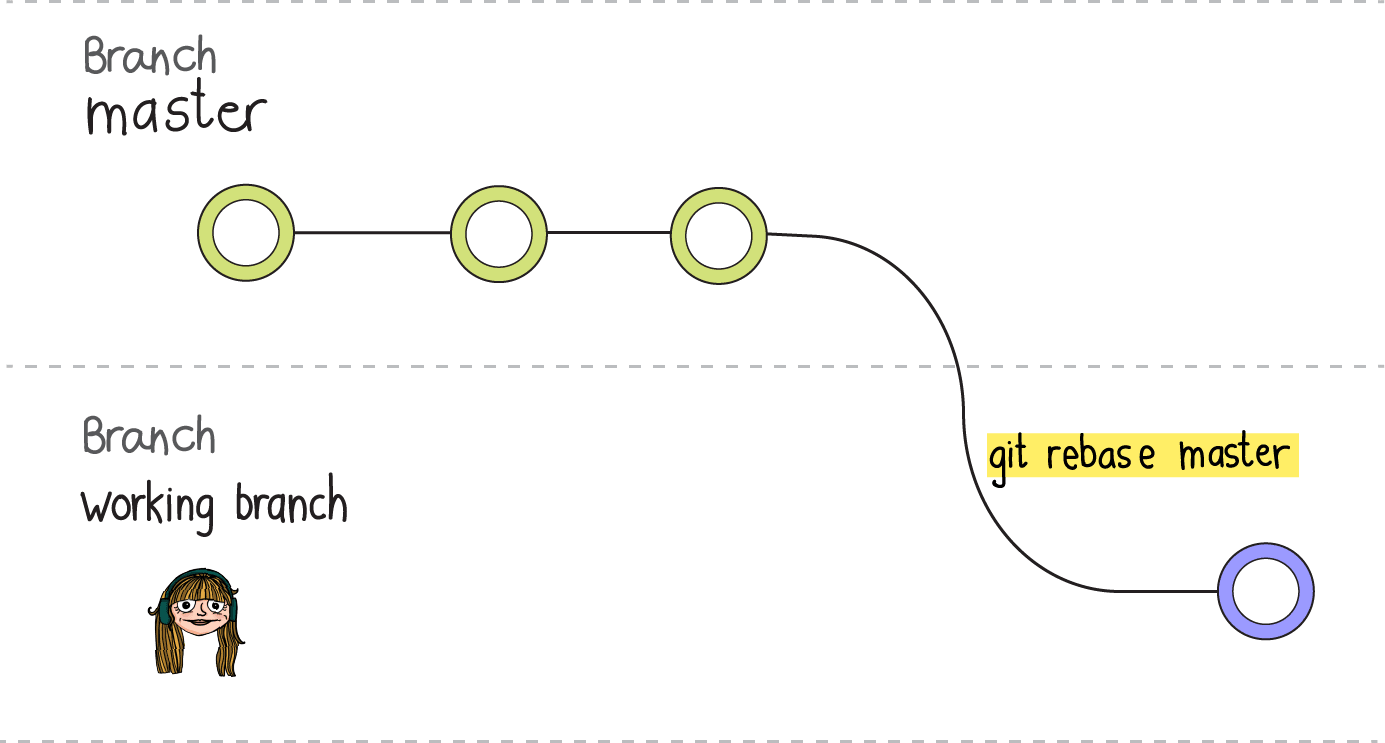
Y después, en su propia rama de trabajo, para actualizarla debe ejecutar git rebase <rama actualizada>.
Bueno, ojalá este ejemplo te haya servido para entender un poco de cómo trabajar con Git. En ese post solo muestro una mínima porción de lo que es Git y en realidad, se me queda el tintero medio lleno, pero espero que te haya ayudado a entender mejor qué es y para qué sirve o haya plantado el bichito para investigar más sobre esta herramienta.
🎁 Un regalito
Si te interesó este tema o te gustaría aprender más, Flo Miranda, desarrolladora en Platanus nos compartió este material que preparó, ¡enjoy!
 flouMicaza
flouMicaza